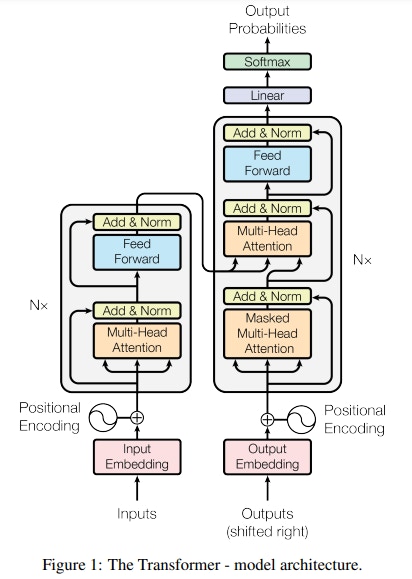
“Attention Is All You Need”
Immaginiamo che il nostro Transformer debba tradurre la frase inglese:
👉 “The cat drinks milk.” (traduzione in italiano: “Il gatto beve latte.”)
Vediamo passo per passo come il modello la elabora.
Fase 1: Tokenizzazione
Il testo viene scomposto in parole (token):
["The", "cat", "drinks", "milk", "."]
Ogni parola viene convertita in un numero (ID univoco) che
il modello può elaborare:
[ 523, 1324, 4563, 987, 34 ]
Fase 2: Embedding
Ogni ID viene trasformato in un vettore numerico (embedding)
che rappresenta il significato della parola in uno spazio multi-dimensionale:
The → [0.2, 0.5, -0.1, 0.7, ...]
cat → [0.4, -0.2, 0.8, 0.1, ...]
drinks → [-0.5, 0.9, 0.3, -0.8, ...]
milk → [0.7, 0.3, -0.6, 0.2, ...]
Fase 3: Positional Encoding
Poiché il Transformer elabora tutte le parole contemporaneamente,
dobbiamo dirgli l’ordine delle parole.
Aggiungiamo un Positional Encoding ai vettori per codificare la posizione:
Word Embedding + Positional Encoding:
The → [0.2+PE, 0.5+PE, -0.1+PE, 0.7+PE, ...]
cat → [0.4+PE, -0.2+PE, 0.8+PE, 0.1+PE, ...]
drinks → [-0.5+PE, 0.9+PE, 0.3+PE, -0.8+PE, ...]
milk → [0.7+PE, 0.3+PE, -0.6+PE, 0.2+PE, ...]
Fase 4: Self-Attention (il cuore del Transformer!)
Ora il modello decide quali parole devono prestare più attenzione alle altre.
Ogni parola viene trasformata in 3 vettori:
• Query (Q): cosa sto cercando?
• Key (K): quanto sono rilevante per altre parole?
• Value (V): qual è la mia informazione da trasferire?
Esempio per “cat”:
Q_cat = [0.4, -0.2, 0.1]
K_cat = [0.3, 0.5, -0.4]
V_cat = [0.8, 0.2, -0.5]
Ora calcoliamo quanto “cat” deve concentrarsi sulle altre parole, moltiplicando Q × K di tutte le parole.
The cat drinks milk
The 0.8 0.1 -0.2 0.3
cat 0.1 1.0 0.5 0.2
drinks -0.2 0.5 1.0 0.7
milk 0.3 0.2 0.7 1.0
Notiamo che “cat” e “drinks” hanno un’attenzione alta (0.5), perché “cat” è molto legato al verbo “drinks”.
Poi applichiamo Softmax per ottenere pesi normalizzati (ovvero percentuali di attenzione):
The: 10%
cat: 40%
drinks: 35%
milk: 15%
Conclusione: “cat” si concentra principalmente su sé stesso (40%) e su “drinks” (35%) perché sono grammaticalmente collegati.
Fase 5: Multi-Head Attention
Abbiamo usato un solo calcolo di attenzione, ma in realtà il Transformer ne esegue diversi contemporaneamente con diversi pesi (multi-head attention). Questo permette di catturare relazioni grammaticali diverse (soggetto-verbo, verbi-oggetti, ecc.).
Fase 6: Feedforward e Normalizzazione
Dopo il self-attention, i nuovi vettori vengono passati a una rete neurale feedforward per elaborare ulteriormente le informazioni e poi normalizzati.
Fase 7: Decoder per la Traduzione
Il decoder prende il risultato dell’encoder e inizia a generare parole in italiano. Funziona in modo simile, ma con un vincolo:
🔹 Il decoder vede solo le parole precedenti, non le future (Masked Self-Attention).
Esempio:
1️⃣ Prima genera “Il”
2️⃣ Poi “gatto”
3️⃣ Poi “beve”
4️⃣ Infine “latte”